
Writen by
Devil
11:17 AM
-
0
Comments
 In today's data-hungry world, building efficient pipelines to ingest, process, and deliver insights is vital. Platforms like Azure empower data engineers to craft robust and scalable pipelines like never before.
In today's data-hungry world, building efficient pipelines to ingest, process, and deliver insights is vital. Platforms like Azure empower data engineers to craft robust and scalable pipelines like never before.
This guide dives deep into the essential components and best practices of crafting Azure data pipelines, equipping you with practical tips to unleash the full potential of your data flow.

Understanding Data Pipelines:
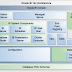
A data pipeline is a series of interconnected processes that extract, transform, and load (ETL) data from various sources into a target destination, typically a data warehouse, database, or analytical system. The goal is to ensure data is collected, cleansed, and transformed into a usable format for analysis and decision-making.
- Components of a Data Pipeline:
- Data Sources: Identify the sources of data, which can range from databases, APIs, logs, and external feeds. Azure offers connectors for various sources like Azure SQL Database, Azure Blob Storage, and more.
- Data Transformation: This stage involves cleansing, enriching, and transforming the raw data into a structured format. Azure Data Factory, Azure Databricks, and Azure HDInsight are popular tools for this purpose.
- Data Movement: Move data efficiently between different storage solutions and services within Azure using Azure Data Factory or Azure Copy Data.
- Data Loading: Load the transformed data into the destination, which could be Azure SQL Data Warehouse, Azure Synapse Analytics, or other databases.
- Orchestration: Tools like Azure Logic Apps or Apache Airflow can be used to orchestrate the entire pipeline, ensuring the right steps are executed in the correct order.
Best Practices for Azure Data Pipeline Design:
- Scalability and Elasticity: Leverage Azure's scalability by using services like Azure Databricks or Azure Synapse Analytics to handle varying data workloads.
- Data Security and Compliance: Implement Azure's security features to protect sensitive data at rest and in transit. Use Azure Key Vault for managing keys and secrets.
- Modularity: Design pipelines as modular components to facilitate reusability and easier maintenance. This also helps in debugging and troubleshooting.
- Monitoring and Logging: Implement robust monitoring and logging using Azure Monitor and Azure Log Analytics to track pipeline performance and identify issues.
- Data Partitioning: When dealing with large datasets, use partitioning strategies to optimize data storage and retrieval efficiency.
- Backup and Disaster Recovery: Ensure data integrity and availability by implementing backup and disaster recovery solutions provided by Azure.
Building a Customer Analytics Pipeline (Example ):
- Let's consider an example of building a customer analytics pipeline in Azure:
- Data Extraction: Extract customer data from Azure SQL Database and external CRM APIs.
- Data Transformation: Use Azure Databricks to cleanse and transform the data, calculating metrics like customer lifetime value and segmentation.
- Data Loading: Load the transformed data into Azure Synapse Analytics for further analysis.
- Orchestration: Use Azure Data Factory to schedule and orchestrate the entire process.
Conclusion:
Creating efficient data pipelines in Azure necessitates a profound comprehension of the platform's services and data engineering principles. By adhering to best practices, taking into account scalability, security, and performance, and harnessing the extensive Azure ecosystem, you can develop data pipelines that deliver precise, timely, and actionable insights, propelling your organization toward success. It is crucial to tailor these practices to your unique use case and consistently iterate to enhance the pipeline's efficiency and dependability.








No comments
Post a Comment